



...and other books as well! Or register for the online video course. You can also donate to support the author directly.

Although Python is my favorite programming language, it isn’t without flaws. Every language has warts (some more than others), and Python is no exception. New Python programmers must learn to avoid some common “gotchas.” Programmers learn this kind of knowledge randomly, from experience, but this chapter collects it in one place. Knowing the programming lore behind these gotchas can help you understand why Python behaves strangely sometimes.
This chapter explains how mutable objects, such as lists and dictionaries, can behave unexpectedly when you modify their contents. You’ll learn how the sort() method doesn’t sort items in an exact alphabetical order and how floating-point numbers can have rounding errors. The inequality operator != has unusual behavior when you chain them together. And you must use a trailing comma when you write tuples that contain a single item. This chapter informs you how to avoid these common gotchas.
Adding or deleting items from a list while looping (that is, iterating) over it with a for or while loop will most likely cause bugs. Consider this scenario: you want to iterate over a list of strings that describe items of clothing and ensure that there is an even number of socks by inserting a matching sock each time a sock is found in the list. The task seems straightforward: iterate over the list’s strings, and when you find 'sock' in a string, such as 'red sock', append another 'red sock' string to the list.
But this code won’t work. It gets caught in an infinite loop, and you’ll have to press Ctrl-Cto interrupt it:
>>> clothes = ['skirt', 'red sock']
>>> for clothing in clothes: # Iterate over the list.
... if 'sock' in clothing: # Find strings with 'sock'.
... clothes.append(clothing) # Add the sock's pair.
... print('Added a sock:', clothing) # Inform the user.
...
Added a sock: red sock
Added a sock: red sock
Added a sock: red sock
--snip--
Added a sock: red sock
Traceback (most recent call last):
File "<stdin>", line 3, in <module>
KeyboardInterruptYou’ll find a visualization of the execution of this code at https://autbor.com/addingloop/.
The problem is that when you append 'red sock' to the clothes list, the list now has a new, third item that it must iterate over: ['skirt', 'red sock', 'red sock']. The for loop reaches the second 'red sock' on the next iteration, so it appends another'red sock' string. This makes the list ['skirt', 'red sock', 'red sock', 'red sock'], giving the list another string for Python to iterate over. This will continue happening, as shown in Figure 8-1, which is why we see the never-ending stream of 'Added a sock.' messages. The loop only stops once the computer runs out of memory and crashes the Python program or until you interrupt it by pressing Ctrl-C.

Figure 8-1: On each iteration of the for loop, a new 'red sock' is appended to the list, which clothing refers to on the next iteration. This cycle repeats forever.
The takeaway is don’t add items to a list while you’re iterating over that list. Instead, use a separate list for the contents of the new, modified list, such as newClothes in this example:
>>> clothes = ['skirt', 'red sock', 'blue sock']
>>> newClothes = []
>>> for clothing in clothes:
... if 'sock' in clothing:
... print('Appending:', clothing)
... newClothes.append(clothing) # We change the newClothes list, not clothes.
...
Appending: red sock
Appending: blue sock
>>> print(newClothes)
['red sock', 'blue sock']
>>> clothes.extend(newClothes) # Appends the items in newClothes to clothes.
>>> print(clothes)
['skirt', 'red sock', 'blue sock', 'red sock', 'blue sock']A visualization of the execution of this code is at https://autbor.com/addingloopfixed/.
Our for loop iterated over the items in the clothes list but didn’t modify clothes inside the loop. Instead, it changed a separate list, newClothes. Then, after the loop, we modify clothes by extending it with the contents of newClothes. You now have a clothes list with matching socks.
Similarly, you shouldn’t delete items from a list while iterating over it. Consider code in which we want to remove any string that isn’t 'hello' from a list. The naive approach is to iterate over the list, deleting the items that don’t match 'hello':
>>> greetings = ['hello', 'hello', 'mello', 'yello', 'hello']
>>> for i, word in enumerate(greetings):
... if word != 'hello': # Remove everything that isn't 'hello'.
... del greetings[i]
...
>>> print(greetings)
['hello', 'hello', 'yello', 'hello']A visualization of the execution of this code is at https://autbor.com/deletingloop/.
It seems that 'yello' is left in the list. The reason is that when the for loop was examining index 2, it deleted 'mello' from the list. But this shifted all the remaining items in the list down one index, moving 'yello' from index 3 to index 2. The next iteration of the loop examines index 3, which is now the last 'hello', as in Figure 8-2. The 'yello' string slipped by unexamined! Don’t remove items from a list while you’re iterating over that list.

Figure 8-2: When the loop removes 'mello', the items in the list shift down one index, causing i to skip over 'yello'.
Instead, create a new list that copies all the items except the ones you want to delete, and then replace the original list. For a bug-free equivalent of the previous example, enter the following code into the interactive shell.
>>> greetings = ['hello', 'hello', 'mello', 'yello', 'hello']
>>> newGreetings = []
>>> for word in greetings:
... if word == 'hello': # Copy everything that is 'hello'.
... newGreetings.append(word)
...
>>> greetings = newGreetings # Replace the original list.
>>> print(greetings)
['hello', 'hello', 'hello']A visualization of the execution of this code is at https://autbor.com/deletingloopfixed/.
Remember that because this code is just a simple loop that creates a list, you can replace it with a list comprehension. The list comprehension doesn’t run faster or use less memory, but it’s shorter to type without losing much readability. Enter the following into the interactive shell, which is equivalent to the code in the previous example:
>>> greetings = ['hello', 'hello', 'mello', 'yello', 'hello']
>>> greetings = [word for word in greetings if word == 'hello']
>>> print(greetings)
['hello', 'hello', 'hello']Not only is the list comprehension more succinct, it also avoids the gotcha that occurs when changing a list while iterating over it.
Although you shouldn’t add or remove items from a list (or any iterable object) while iterating over it, it’s fine to modify the list’s contents. For example, say we have a list of numbers as strings: ['1', '2', '3', '4', '5']. We can convert this list of strings into a list of integers [1, 2, 3, 4, 5] while iterating over the list:
>>> numbers = ['1', '2', '3', '4', '5']
>>> for i, number in enumerate(numbers):
... numbers[i] = int(number)
...
>>> numbers
[1, 2, 3, 4, 5]A visualization of the execution of this code is at https://autbor.com/covertstringnumbers. Modifying the items in the list is fine; it’s changing the number of items in the list that is bug prone.
Another possible way to add or delete items in a list safely is by iterating backward from the end of the list to the beginning. This way, you can delete items from the list as you iterate over it, or add items to the list as long as you add them to the end of the list. For example, enter the following code, which removes even integers from the someInts list.
>>> someInts = [1, 7, 4, 5]
>>> for i in range(len(someInts)):
...
... if someInts[i] % 2 == 0:
... del someInts[i]
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
IndexError: list index out of range
>>> someInts = [1, 7, 4, 5]
>>> for i in range(len(someInts) - 1, -1, -1):
... if someInts[i] % 2 == 0:
... del someInts[i]
...
>>> someInts
[1, 7, 5]This code works because none of the items that the loop will iterate over in the future ever have their index changed. But the repeated shifting up of values after the deleted value makes this technique inefficient for long lists. A visualization of the execution of this code is at https://autbor.com/iteratebackwards1. You can see the difference between iterating forward and backward in Figure 8-3.
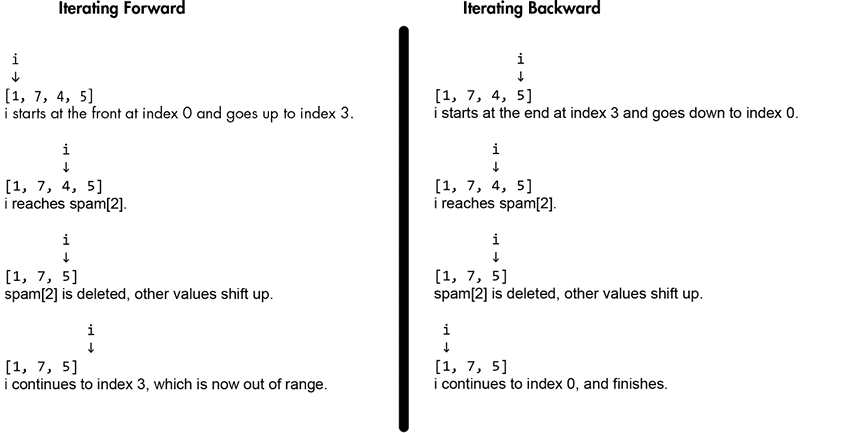
Figure 8-3: Removing even numbers from a list while iterating forward (left) and backward (right)
Similarly, you can add items to the end of the list as you iterate backward over it. Enter the following into the interactive shell, which appends a copy of any even integers in the someInts list to the end of the list:
>>> someInts = [1, 7, 4, 5]
>>> for i in range(len(someInts) - 1, -1, -1):
... if someInts[i] % 2 == 0:
... someInts.append(someInts[i])
...
>>> someInts
[1, 7, 4, 5, 4]A visualization of the execution of this code is at https://autbor.com/iteratebackwards2. By iterating backward, we can append items to or remove items from the list. But this can be tricky to do correctly because slight changes to this basic technique could end up introducing bugs. It’s much simpler to create a new list rather than modifying the original list. As Python core developer Raymond Hettinger put it:
It’s better to think of variables as labels or name tags that refer to objects rather than as boxes that contain objects. This mental model is especially useful when it comes to modifying mutable objects: objects such as lists, dictionaries, and sets whose value can mutate (that is, change). A common gotcha occurs when copying one variable that refers to a mutable object to another variable and thinking that the actual object is being copied. In Python, assignment statements never copy objects; they only copy the references to an object. (Python developer Ned Batchelder has a great PyCon 2015 talk on this idea titled, “Facts and Myths about Python Names and Values.” Watch it at https://youtu.be/_AEJHKGk9ns.)
For example, enter the following code into the interactive shell, and note that even though we change the spam variable only, the cheese variable changes as well:
>>> spam = ['cat', 'dog', 'eel']
>>> cheese = spam
>>> spam
['cat', 'dog', 'eel']
>>> cheese
['cat', 'dog', 'eel']
>>> spam[2] = 'MOOSE'
>>> spam
['cat', 'dog', 'MOOSE']
>>> cheese
['cat', 'dog', 'MOOSE']
>>> id(cheese), id(spam)
2356896337288, 2356896337288A visualization of the execution of this code is at https://autbor.com/listcopygotcha1. If you think that cheese = spam copied the list object, you might be surprised that cheese seems to have changed even though we only modified spam. But assignment statements never copy objects, only references to objects. The assignment statement cheese = spam makes cheeserefer to the same list object in the computer’s memory as spam. It doesn’t duplicate the list object. This is why changing spam also changes cheese: both variables refer to the same list object.
The same principle applies to mutable objects passed to a function call. Enter the following into the interactive shell, and note that the global variable spam and the local parameter (remember, parameters are variables defined in the function’s def statement) theList both refer to the same object:
>>> def printIdOfParam(theList):
... print(id(theList))
...
>>> eggs = ['cat', 'dog', 'eel']
>>> print(id(eggs))
2356893256136
>>> printIdOfParam(eggs)
2356893256136A visualization of the execution of this code is at https://autbor.com/listcopygotcha2. Notice that the identities returned by id() for eggs and theList are the same, meaning these variables refer to the same list object. The eggs variable’s list object wasn’t copied to theList; rather, the reference was copied, which is why both variables refer to the same list. A reference is only a few bytes in size, but imagine if Python copied the entire list instead of just the reference. If eggs contained a billion items instead of just three, passing it to the printIdOfParam() function would require copying this giant list. This would eat up gigabytes of memory just to do a simple function call! That’s why Python assignment only copies references and never copies objects.
One way to prevent this gotcha is to make a copy of the list object (not just the reference) with the copy.copy() function. Enter the following into the interactive shell:
>>> import copy
>>> bacon = [2, 4, 8, 16]
>>> ham = copy.copy(bacon)
>>> id(bacon), id(ham)
(2356896337352, 2356896337480)
>>> bacon[0] = 'CHANGED'
>>> bacon
['CHANGED', 4, 8, 16]
>>> ham
[2, 4, 8, 16]
>>> id(bacon), id(ham)
(2356896337352, 2356896337480)A visualization of the execution of this code is at https://autbor.com/copycopy1. The ham variable refers to a copied list object rather than the original list object referred to by bacon, so it doesn’t suffer from this gotcha.
But just as variables are like labels or name tags rather than boxes that contain objects, lists also contain labels or name tags that refer to objects rather than the actual objects. If your list contains other lists, copy.copy() only copies the references to these inner lists. Enter the following into the interactive shell to see this problem:
>>> import copy
>>> bacon = [[1, 2], [3, 4]]
>>> ham = copy.copy(bacon)
>>> id(bacon), id(ham)
(2356896466248, 2356896375368)
>>> bacon.append('APPENDED')
>>> bacon
[[1, 2], [3, 4], 'APPENDED']
>>> ham
[[1, 2], [3, 4]]
>>> bacon[0][0] = 'CHANGED'
>>> bacon
[['CHANGED', 2], [3, 4], 'APPENDED']
>>> ham
[['CHANGED', 2], [3, 4]]
>>> id(bacon[0]), id(ham[0])
(2356896337480, 2356896337480)A visualization of the execution of this code is at https://autbor.com/copycopy2. Although bacon and ham are two different list objects, they refer to the same [1, 2] and [3, 4] inner lists, so changes to these inner lists get reflected in both variables, even though we used copy.copy(). The solution is to use copy.deepcopy(), which will make copies of any list objects inside the list object being copied (and any list objects in those list objects, and so on). Enter the following into the interactive shell:
>>> import copy
>>> bacon = [[1, 2], [3, 4]]
>>> ham = copy.deepcopy(bacon)
>>> id(bacon[0]), id(ham[0])
(2356896337352, 2356896466184)
>>> bacon[0][0] = 'CHANGED'
>>> bacon
[['CHANGED', 2], [3, 4]]
>>> ham
[[1, 2], [3, 4]]A visualization of the execution of this code is at https://autbor.com/copydeepcopy. Although copy.deepcopy() is slightly slower than copy.copy(), it’s safer to use if you don’t know whether the list being copied contains other lists (or other mutable objects like dictionaries or sets). My general advice is to always use copy.deepcopy(): it might prevent subtle bugs, and the slowdown in your code probably won’t be noticeable.
Python allows you to set default arguments for parameters in the functions you define. If a user doesn’t explicitly set a parameter, the function will execute using the default argument. This is useful when most calls to the function use the same argument, because default arguments make the parameter optional. For example, passing None for the split() method makes it split on whitespace characters, but None is also the default argument: calling 'cat dog'.split() does the same thing as calling 'cat dog'.split(None). The function uses the default argument for the parameter’s argument unless the caller passes one in.
But you should never set a mutable object, such as a list or dictionary, as a default argument. To see how this causes bugs, look at the following example, which defines an addIngredient() function that adds an ingredient string to a list that represents a sandwich. Because the first and last items of this list are often 'bread', the mutable list ['bread', 'bread'] is used as a default argument:
>>> def addIngredient(ingredient, sandwich=['bread', 'bread']):
... sandwich.insert(1, ingredient)
... return sandwich
...
>>> mySandwich = addIngredient('avocado')
>>> mySandwich
['bread', 'avocado', 'bread']But using a mutable object, such as a list like ['bread', 'bread'], for the default argument has a subtle problem: the list is created when the function’s def statement executes, not each time the function is called. This means that only one ['bread', 'bread'] list object gets created, because we only define the addIngredient() function once. But each function call to addIngredient() will be reusing this list. This leads to unexpected behavior, like the following:
>>> mySandwich = addIngredient('avocado')
>>> mySandwich
['bread', 'avocado', 'bread']
>>> anotherSandwich = addIngredient('lettuce')
>>> anotherSandwich
['bread', 'lettuce', 'avocado', 'bread']Because addIngredient('lettuce') ends up using the same default argument list as the previous calls, which already had 'avocado' added to it, instead of ['bread', 'lettuce', 'bread'] the function returns ['bread', 'lettuce', 'avocado', 'bread']. The 'avocado' string appears again because the list for the sandwich parameter is the same as the last function call. Only one ['bread', 'bread'] list was created, because the function’s def statement only executes once, not each time the function is called. A visualization of the execution of this code is at https://autbor.com/sandwich.
If you need to use a list or dictionary as a default argument, the pythonic solution is to set the default argument to None. Then have code that checks for this and supplies a new list or dictionary whenever the function is called. This ensures that the function creates a new mutable object each time the function is called instead of just once when the function is defined, such as in the following example:
>>> def addIngredient(ingredient, sandwich=None):
... if sandwich is None:
... sandwich = ['bread', 'bread']
... sandwich.insert(1, ingredient)
... return sandwich
...
>>> firstSandwich = addIngredient('cranberries')
>>> firstSandwich
['bread', 'cranberries', 'bread']
>>> secondSandwich = addIngredient('lettuce')
>>> secondSandwich
['bread', 'lettuce', 'bread']
>>> id(firstSandwich) == id(secondSandwich)
1 FalseNotice that firstSandwich and secondSandwich don’t share the same list reference 1 because sandwich = ['bread', 'bread'] creates a new list object each time addIngredient() is called, not just once when addIngredient() is defined.
Mutable data types include lists, dictionaries, sets, and objects made from the class statement. Don’t put objects of these types as default arguments in a def statement.
In Python, strings are immutable objects. This means that string values can’t change, and any code that seems to modify the string is actually creating a new string object. For example, each of the following operations changes the content of the spam variable, not by changing the string value, but by replacing it with a new string value that has a new identity:
>>> spam = 'Hello'
>>> id(spam), spam
(38330864, 'Hello')
>>> spam = spam + ' world!'
>>> id(spam), spam
(38329712, 'Hello world!')
>>> spam = spam.upper()
>>> id(spam), spam
(38329648, 'HELLO WORLD!')
>>> spam = 'Hi'
>>> id(spam), spam
(38395568, 'Hi')
>>> spam = f'{spam} world!'
>>> id(spam), spam
(38330864, 'Hi world!')Notice that each call to id(spam) returns a different identity, because the string object in spam isn’t being changed: it’s being replaced by a whole new string object with a different identity. Creating new strings by using f-strings, the format() string method, or the %s format specifiers also creates new string objects, just like string concatenation. Normally, this technical detail doesn’t matter. Python is a high-level language that handles many of these details for you so you can focus on creating your program.
But building a string through a large number of string concatenations can slow down your programs. Each iteration of the loop creates a new string object and discards the old string object: in code, this looks like concatenations inside a for or while loop, as in the following:
>>> finalString = ''
>>> for i in range(100000):
... finalString += 'spam '
...
>>> finalString
spam spam spam spam spam spam spam spam spam spam spam spam --snip--Because the finalString += 'spam ' happens 100,000 times inside the loop, Python is performing 100,000 string concatenations. The CPU has to create these intermediate string values by concatenating the current finalString with 'spam ', put them into memory, and then almost immediately discard them on the next iteration. This is a lot of wasted effort, because we only care about the final string.
The pythonic way to build strings is to append the smaller strings to a list and then join the list together into one string. This method still creates 100,000 string objects, but it only performs one string concatenation, when it calls join(). For example, the following code produces the equivalent finalString but without the intermediate string concatenations:
>>> finalString = []
>>> for i in range(100000):
... finalString.append('spam ')
...
>>> finalString = ''.join(finalString)
>>> finalString
spam spam spam spam spam spam spam spam spam spam spam spam --snip--When I measure the runtime of these two pieces of code on my machine, the list appending approach is 10 times faster than the string concatenation approach. (Chapter 13 describes how to measure how fast your programs run.) This difference becomes greater the more iterations the for loop makes. But when you change range(100000) to range(100), although concatenation remains slower than list appending, the speed difference is negligible. You don’t need to obsessively avoid string concatenation, f-strings, the format() string method, or %s format specifiers in every case. The speed only significantly improves when you’re performing large numbers of string concatenations.
Python frees you from having to think about many underlying details. This allows programmers to write software quickly, and as mentioned earlier, programmer time is more valuable than CPU time. But there are cases when it’s good to understand details, such as the difference between immutable strings and mutable lists, to avoid tripping on a gotcha, like building strings through concatenation.
Understanding sorting algorithms—algorithms that systematically arrange values by some established order—is an important foundation for a computer science education. But this isn’t a computer science book; we don’t need to know these algorithms, because we can just call Python’s sort() method. However, you’ll notice that sort() has some odd sorting behavior that puts a capital Z before a lowercase a:
>>> letters = ['z', 'A', 'a', 'Z']
>>> letters.sort()
>>> letters
['A', 'Z', 'a', 'z']The American Standard Code for Information Interchange (ASCII, pronounced “ask-ee”) is a mapping between numeric codes (called code points or ordinals) and text characters. The sort() method uses ASCII-betical sorting (a general term meaning sorted by ordinal number) rather than alphabetical sorting. In the ASCII system, A is represented by code point 65, B by 66, and so on, up to Z by 90. The lowercase a is represented by code point 97, b by 98, and so on, up to z by 122. When sorting by ASCII, uppercase Z (code point 90) comes before lowercase a (code point 97).
Although it was almost universal in Western computing prior to and throughout the 1990s, ASCII is an American standard only: there’s a code point for the dollar sign, $ (code point 36), but there is no code point for the British pound sign, £. ASCII has largely been replaced by Unicode, because Unicode contains all of ASCII’s code points and more than 100,000 other code points.
You can get the code point, or ordinal, of a character by passing it to the ord() function. You can do the reverse by passing an ordinal integer to the chr() function, which returns a string of the character. For example, enter the following into the interactive shell:
>>> ord('a')
97
>>> chr(97)
'a'If you want to make an alphabetical sort, pass the str.lower method to the key parameter. This sorts the list as if the values had the lower() string method called on them:
>>> letters = ['z', 'A', 'a', 'Z']
>>> letters.sort(key=str.lower)
>>> letters
['A', 'a', 'z', 'Z']Note that the actual strings in the list aren’t converted to lowercase; they’re only sorted as if they were. Ned Batchelder provides more information about Unicode and code points in his talk “Pragmatic Unicode, or, How Do I Stop the Pain?” at https://nedbatchelder.com/text/unipain.html.
Incidentally, the sorting algorithm that Python’s sort() method uses is Timsort, which was designed by Python core developer and “Zen of Python” author Tim Peters. It’s a hybrid of the merge sort and insertion sort algorithms, and is described at https://en.wikipedia.org/wiki/Timsort.
Computers can only store the digits of the binary number system, which are 1 and 0. To represent the decimal numbers we’re familiar with, we need to translate a number like 3.14 into a series of binary ones and zeros. Computers do this according to the IEEE 754 standard, published by the Institute of Electrical and Electronics Engineers (IEEE, pronounced “eye-triple-ee”). For simplicity, these details are hidden from the programmer, allowing you to type numbers with decimal points and ignore the decimal-to-binary conversion process:
>>> 0.3
0.3Although the details of specific cases are beyond the scope of this book, the IEEE 754 representation of a floating-point number won’t always exactly match the decimal number. One well-known example is 0.1:
>>> 0.1 + 0.1 + 0.1
0.30000000000000004
>>> 0.3 == (0.1 + 0.1 + 0.1)
FalseThis bizarre, slightly inaccurate sum is the result of rounding errors caused by how computers represent and process floating-point numbers. This isn’t a Python gotcha; the IEEE 754 standard is a hardware standard implemented directly into a CPU’s floating-point circuits. You’ll get the same results in C++, JavaScript, and every other language that runs on a CPU that uses IEEE 754 (which is effectively every CPU in the world).
The IEEE 754 standard, again for technical reasons beyond the scope of this book, also cannot represent all whole number values greater than 253. For example, 253 and 253 + 1, as float values, both round to 9007199254740992.0:
>>> float(2**53) == float(2**53) + 1
TrueAs long as you use the floating-point data type, there’s no workaround for these rounding errors. But don’t worry. Unless you’re writing software for a bank, a nuclear reactor, or a bank’s nuclear reactor, rounding errors are small enough that they’ll likely not be an important issue for your program. Often, you can resolve them by using integers with smaller denominations: for example, 133 cents instead of 1.33 dollars or 200 milliseconds instead of 0.2 seconds. This way, 10 + 10 + 10 adds up to 30 cents or milliseconds rather than 0.1 + 0.1 + 0.1 adding up to 0.30000000000000004 dollars or seconds.
But if you need exact precision, say for scientific or financial calculations, use Python’s built-in decimal module, which is documented at https://docs.python.org/3/library/decimal.html. Although they’re slower, Decimal objects are precise replacements for float values. For example, decimal.Decimal('0.1') creates an object that represents the exact number 0.1 without the imprecision that a 0.1 float value would have.
Passing the float value 0.1 to decimal.Decimal() creates a Decimal object that has the same imprecision as a float value, which is why the resulting Decimal object isn’t exactly Decimal('0.1'). Instead, pass a string of the float value to decimal.Decimal(). To illustrate this point, enter the following into the interactive shell:
>>> import decimal
>>> d = decimal.Decimal(0.1)
>>> d
Decimal('0.1000000000000000055511151231257827021181583404541015625')
>>> d = decimal.Decimal('0.1')
>>> d
Decimal('0.1')
>>> d + d + d
Decimal('0.3')Integers don’t have rounding errors, so it’s always safe to pass them to decimal.Decimal(). Enter the following into the interactive shell:
>>> 10 + d
Decimal('10.1')
>>> d * 3
Decimal('0.3')
>>> 1 - d
Decimal('0.9')
>>> d + 0.1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'decimal.Decimal' and 'float'But Decimal objects don’t have unlimited precision; they simply have a predictable, well-established level of precision. For example, consider the following operations:
>>> import decimal
>>> d = decimal.Decimal(1) / 3
>>> d
Decimal('0.3333333333333333333333333333')
>>> d * 3
Decimal('0.9999999999999999999999999999')
>>> (d * 3) == 1 # d is not exactly 1/3
FalseThe expression decimal.Decimal(1) / 3 evaluates to a value that isn’t exactly one-third. But by default, it’ll be precise to 28 significant digits. You can find out how many significant digits the decimal module uses by accessing the decimal.getcontext().prec attribute. (Technically, prec is an attribute of the Context object returned by getcontext(), but it’s convenient to put it on one line.) You can change this attribute so that all Decimal objects created afterward use this new level of precision. The following interactive shell example lowers the precision from the original 28 significant digits to 2:
>>> import decimal
>>> decimal.getcontext().prec
28
>>> decimal.getcontext().prec = 2
>>> decimal.Decimal(1) / 3
Decimal('0.33')The decimal module provides you with fine control over how numbers interact with each other. The decimal module is documented in full at https://docs.python.org/3/library/decimal.html.
Chaining comparison operators like 18 < age < 35 or chaining assignment operators like six = halfDozen = 6 are handy shortcuts for (18 < age) and (age < 35) and six = 6; halfDozen = 6, respectively.
But don’t chain the != comparison operator. You might think the following code checks whether all three variables have different values from each other, because the following expression evaluates to True:
>>> a = 'cat'
>>> b = 'dog'
>>> c = 'moose'
>>> a != b != c
TrueBut this chain is actually equivalent to (a != b) and (b != c). This means that a could still be the same as c and the a != b != c expression would still be True:
>>> a = 'cat'
>>> b = 'dog'
>>> c = 'cat'
>>> a != b != c
TrueThis bug is subtle and the code is misleading, so it’s best to avoid using chained != operators altogether.
When writing tuple values in your code, keep in mind that you’ll still need a trailing comma even if the tuple only contains a single item. Although the value (42, ) is a tuple that contains the integer 42, the value (42) is simply the integer 42. The parentheses in (42) are similar to those used in the expression (20 + 1) * 2, which evaluates to the integer value 42. Forgetting the comma can lead to this:
>>> spam = ('cat', 'dog', 'moose')
>>> spam[0]
'cat'
>>> spam = ('cat')
1 >>> spam[0]
'c'
2 >>> spam = ('cat', )
>>> spam[0]
'cat'Without a comma, ('cat') evaluates to the string value, which is why spam[0] evaluates to the first character of the string, 'c'1. The trailing comma is required for the parentheses to be recognized as a tuple value 2. In Python, the commas make a tuple more than the parentheses.
Miscommunication happens in every language, even in programming languages. Python has a few gotchas that can trap the unwary. Even if they rarely come up, it’s best to know about them so you can quickly recognize and debug the problems they can cause.
Although it’s possible to add or remove items from a list while iterating over that list, it’s a potential source of bugs. It’s much safer to iterate over a copy of the list and then make changes to the original. When you do make copies of a list (or any other mutable object), remember that assignment statements copy only the reference to the object, not the actual object. You can use the copy.deepcopy() function to make copies of the object (and copies of any objects it references).
You shouldn’t use mutable objects in def statements for default arguments, because they’re created once when the def statement is run rather than each time the function is called. A better idea is to make the default argument None, and then add code that checks for None and creates a mutable object when the function is called.
A subtle gotcha is the string concatenation of several smaller strings with the + operator in a loop. For small numbers of iteration, this syntax is fine. But under the hood, Python is constantly creating and destroying string objects on each iteration. A better approach is to append the smaller strings into a list and then call the join() operator to create the final string.
The sort() method sorts by numeric code points, which isn’t the same as alphabetical order: uppercase Z is sorted before lowercase a. To fix this issue, you can call sort(key=str.lower).
Floating-point numbers have slight rounding errors as a side effect of how they represent numbers. For most programs, this isn’t important. But if it does matter for your program, you can use Python’s decimal module.
Never chain together != operators, because expressions like 'cat' != 'dog' != 'cat' will, confusingly, evaluate to True.
Although this chapter described the Python gotchas that you’re most likely to encounter, they don’t occur daily in most real-world code. Python does a great job of minimizing the surprises you might find in your programs. In the next chapter, we’ll cover some gotchas that are even rarer and downright bizarre. It’s almost impossible that you’ll ever encounter these Python language oddities if you aren’t searching for them, but it’ll be fun to explore the reasons they exist.